
微服务的数据处理注意事项
本文介绍在微服务体系结构中管理数据时的注意事项。 由于每个微服务管理自身的数据,因此,数据完整性和数据一致性是关键的挑战。
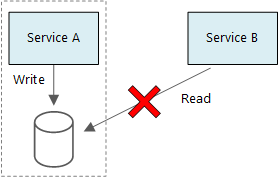
微服务的基本原则是每个服务管理其自身的数据。 两个服务不应共享数据存储。 相反,每个服务负责管理维护自身的专用数据存储,其他服务不能直接访问该存储。
制定此规则的原因是避免服务之间出现意外耦合 - 如果服务共享相同的基础数据架构,就会出现这种情况。 如果对数据架构做了某项更改,必须在依赖于该数据库的每个服务之间协调该项更改。 通过隔离每个服务的数据存储,我们可以限制更改范围,并保持真正独立部署的灵活性。 另一个原因是,每个微服务可能有自身的数据模型、查询或读/写模式。 使用共享的数据存储会限制每个团队为其特定服务优化数据存储的能力。
此方法自然会导致 polyglot 持久性 ,即在单个应用程序中使用多个数据存储技术。 一个服务可能需要文档数据库的“读时架构”功能。 另一个服务可能需要 RDBMS 提供的引用完整性。 每个团队可以根据其服务任意做出最佳选择。 有关 Polyglot 持久性一般原则的详细信息,请参阅使用最佳的数据存储完成作业。
备注
服务可以共享相同的物理数据库服务器。 当服务共享相同的架构或者在相同的数据库表集中读取和写入数据时,就会出现问题。
挑战
这种分布式数据管理方法存在一些挑战。 首先,数据存储之间可能出现冗余,即同一个数据项显示在多个位置。 例如,数据一开始存储为事务的一部分,然后又存储在其他位置供分析、报告或存档。 重复或分区的数据可能导致数据完整性和一致性问题。 当数据关系跨越多个服务时,无法使用传统的数据管理方法来实施关系。
传统数据建模使用 “一种事实在同一位置” 的规则。每个实体在架构中仅出现一次。 其他实体可以保留对该实体的引用,但不能复制它。 传统方法的明显优势是在一个位置进行更新,从而可以避免数据一致性问题。 在微服务体系结构中,必须考虑如何在服务之间传播更新,以及在未实施强一致性的情况下,如果数据出现在多个位置,应如何管理最终一致性。
数据管理方法
不存在以一应百的方法,不过,在微服务体系结构中管理数据时,可以遵循一些通用准则。
如果可能,应采用最终一致性。 了解系统中需要强一致性或 ACID 事务的位置,以及可接受最终一致性的位置。
需要强一致性保证时,一个服务可以代表给定实体的事实源(通过 API 公开)。 其他服务可以保留自身的数据副本或数据子集,这些数据与主数据最终保持一致,但不被视为事实源。 例如,假设有一个包含客户订单服务和推荐服务的电子商务系统。 推荐服务可以侦听来自订单服务的事件,但如果客户请求退款,则只有订单服务包含完整的交易历史记录,而推荐服务则没有此类信息。
对于事务,可以使用计划程序代理监督程序和补偿事务等模式来保持多个服务之间的数据一致性。 可能需要存储附加的数据片段用于捕获跨多个服务的工作单元的状态,以免多个服务之间发生部分失败。 例如,在处理多步骤事务的过程中,可将某个工作项保留在持久队列中。
只存储服务所需的数据。 服务可能只需要有关域实体的一部分信息。 例如,在“交货”边界上下文中,我们需要知道哪个客户已关联到特定的交付项。 但我们并不需要客户的帐单地址,由帐户界定的上下文进行管理。 在此情况下,认真考虑域的要求并使用 DDD 方法可能有所帮助。
考虑服务是否是内聚且松散耦合的。 如果两个服务持续相互交换信息,导致出现琐碎 API,则你可能需要通过合并两个服务或重构其功能来重绘服务边界。
使用事件驱动的体系结构样式。 在此体系结构样式中,当某个服务的公共模型或实体发生更改时,该服务会发布事件。 相关的服务可以订阅这些事件。 例如,另一个服务可以使用事件来构造更适合用于查询的具体化数据视图。
拥有事件的服务应发布可用于自动序列化和反序列化事件的架构,以免发布方与订阅方之间发生紧密耦合。 考虑使用 JSON 架构,或者 Microsoft Bond、Protobuf 或 Avro 等框架。
在大规模运营中,事件可能成为系统中的瓶颈,因此,请考虑使用聚合或批处理来减少总负载。
示例:为无人机传递应用程序选择数据存储
本系列文章中的前面文章讨论了无人机交付服务作为正在运行的示例。 可在 此处阅读有关该方案和相应引用实现的详细信息。
概括而言,此应用程序定义了多个微服务,用于按无人机计划交付。 当用户计划新交付时,客户端请求会包含有关传递的信息(如分拣和下车位置)以及有关包的信息,例如大小和权重。 此信息定义工作单元。
各种后端服务将会处理请求中的不同信息部分,并且包含不同的读取和写入配置文件。
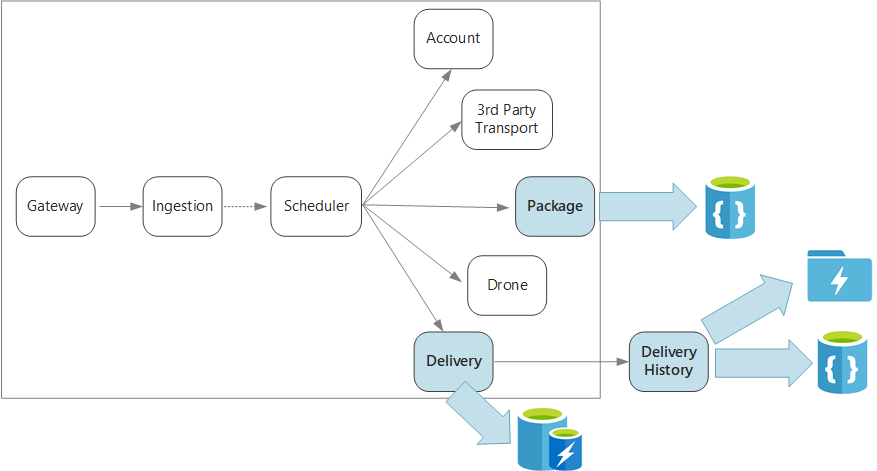
交付服务
交付服务存储有关当前已安排的或正在处理的每项交付的信息。 它会侦听来自无人机的事件,并跟踪正在进行的交付的状态。 此外,它会发送包含交付状态更新内容的域事件。
用户在等待包裹期间,预期会经常检查交付状态。 因此,交付服务需要一个具有突出吞吐量(读取和写入)而不是持久性的数据存储。 此外,交付服务不会执行任何复杂的查询或分析,而只是提取给定交付的最新状态。 交付服务团队选择了用于 Redis 的 Azure 缓存,以提高读写性能。 Redis 中存储的信息的生存期相对较短。 交付完成后,交付历史记录服务即是记录系统。
交付历史记录服务
交付历史记录服务侦听来自交付服务的交付状态事件。 它将此数据存储在长期存储中。 此历史数据有两种不同的用例,每种用例有不同的数据存储要求。
第一种方案是聚合用于数据分析的数据,以优化业务或改进服务质量。 请注意,交付历史记录服务不执行实际的数据分析。 它只是负责引入和存储。 对于此方案,必须优化存储以针对大量数据执行数据分析,并使用“读时架构”方法来适应各种数据源。
另一种方案是在完成交付后,让用户查找交付历史记录。 为获得最佳性能,Microsoft 建议将时序数据存储在 Data Lake 中已按日期分区的文件夹内。 但是,在按 ID 查找单个记录时,该结构并不是最佳的。 除非同时知道时间戳,否则按 ID 查找需要扫描整个集合。 因此,交付历史记录服务还会将一部分历史数据存储在 Cosmos DB 中,以加快查找速度。 记录不需要无限期保留在 Cosmos DB 中。 可以存档较早的传递—例如,在一个月后。 为此,可以偶尔运行批处理。
包裹服务
包裹服务存储有关所有包裹的信息。 包裹的存储要求如下:
- 长期存储。
- 能够处理大量包裹,需要较高的写入吞吐量。
- 支持按包裹 ID 执行简单查询。 无需复杂的联接,不存在引用完整性方面的要求。
因为包数据不是关系的,所以,面向文档的数据库是适当的,Cosmos DB 可以使用分片集合实现高吞吐量。 使用包裹服务的团队比较熟悉 MEAN 堆栈(MongoDB、Express.js、AngularJS 和 Node.js),因此他们选择了适用于 Cosmos DB 的 MongoDB API。 这样,他们便可以利用现有的 MongoDB 经验,同时获得 Cosmos DB的优势。






